


웹사이트 SEO (검색엔진최적화) 작업을 진행하는 과정 중 포털사이트 검색 키워드에 대한 검색량, 연령, 성별 데이터를 수집하는 단계가 있습니다. 대부분의 대형 포털사이트는 해당 데이터들을 API 서버를 통해 클라이언트에게 공개합니다. 이번 게시글을 통해서 국내 대형 포털 중 하나인 네이버에 검색 트렌드에 대한 데이터를 API호출을 통해 요청해보도록 하겠습니다.
데이터 요청 과정은 다음과 같습니다 : 네이버API 서비스 신청 > 파이썬을 통한 API 호출 및 응답 > 데이터 가공
//작업 환경
Mac(Intel) Os 12.6 / VsCode for Mac / Python3.9.6 / pip3 22.2.2- 네이버 API 서비스 신청
- 네이버 개발자 센터 검색 트렌드 API 신청
- 파이썬을 통한 API 호출
- 초기 설정 및 모듈 설치
- API 호출
- 파이썬을 통한 데이터 가공
- 데이터 활용을 위한 모듈 설치
- .csv로 가공 및 저장
네이버 API 서비스 신청
네이버 개발자 센터 검색 트렌드 API 신청

네이버 개발자센터 홈페이지 방문합니다.
로그인한 상태로 상단에 Application > 애플리케이션 등록 방문 으로 접속합니다.

네이버 API 사용을 위해서 인증과정을 거쳐야 합니다. 과정은 : 약관동의 > 계정 정보 등록 > 애플리케이션 등록
우리는 검색 키워드에 대한 정보를 수집하기 위해 통합검색어 트렌드 API를 활용할 것 입니다.
https://developers.naver.com/products/service-api/datalab/datalab.md

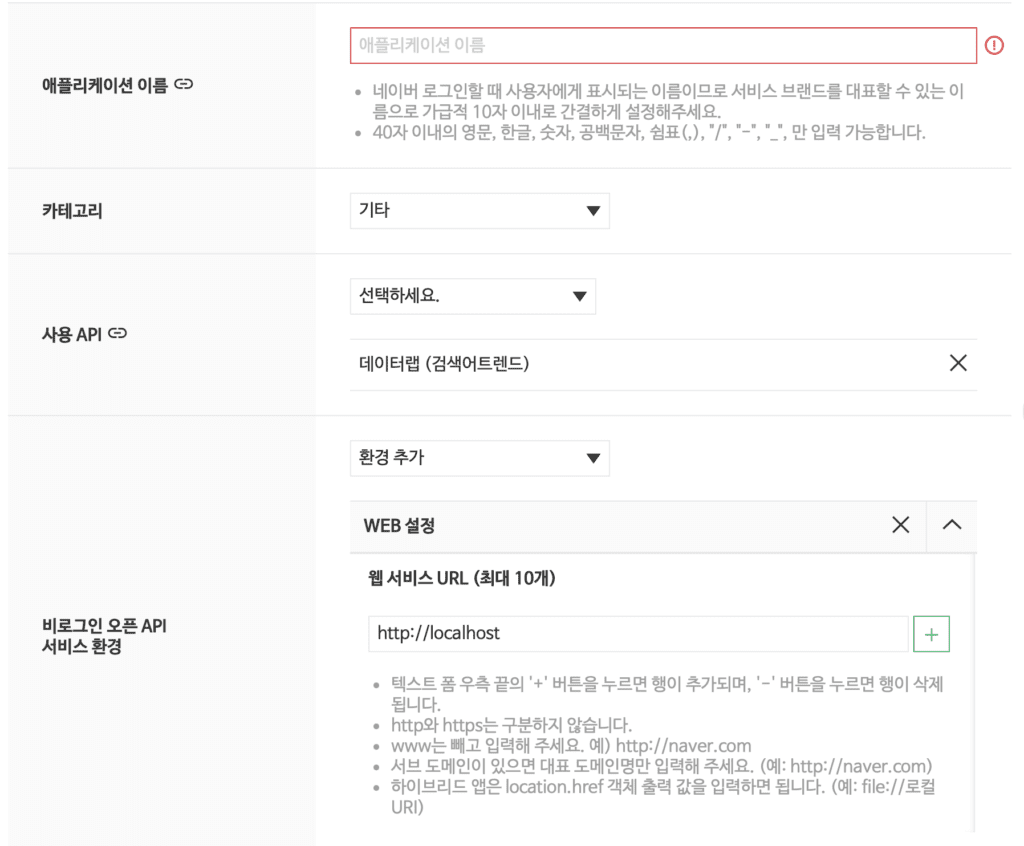
사용 API에서 데이터랩 (검색어 트렌드)를 설정하고 아래 웹 서비스 URL은 http://localhost로 설정합니다.
위 과정을 마무리하면 API 호출을 위한 Client ID와 Client Secret이 발급됩니다. 발급된 아이디와 비밀번호를 통해 파이썬에서 네이버 API에 데이터를 요청하기 때문에 기억해둡시다.
파이썬을 통한 API 호출
초기 설정 및 모듈 설치
파이썬을 통해 API호출을 위해서 필요한 모듈을 pip3를 통해 미리 설치하자. 아래 명령어를 터미널에 입력하면 됩니다.
pip3 list
pip3 pandas
pip3 install urllib
pip3 install json사용자의 컴퓨터에 이미 설치되어 있는 경우도 있기 때문에 없는 모듈만 선택해서 설치하면 됩니다.
API 호출
우선 검색 데이터 API를 호출하는 전체 코드를 확인하고 상단부터 차례대로 분석합시다.
import pandas as pd
import urllib.request
import json
client_id = "발급받은id"
client_secret = "발급받은password"
url = "https://openapi.naver.com/v1/datalab/search"
body = "{\
\"startDate\":\"2022-10-01\",\
\"endDate\":\"2022-10-04\",\
\"timeUnit\":\"date\",\
\"keywordGroups\":[{\"groupName\":\"한글\",\"keywords\":[\"한글\",\"korean\"]},\
{\"groupName\":\"영어\",\"keywords\":[\"영어\",\"english\"]}\
],\
\"device\":\"pc\",\
\"ages\":[\"1\",\"2\"],\
\"gender\":\"f\"\
}";
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
request.add_header("Content-Type","application/json")
response = urllib.request.urlopen(request, data=body.encode("utf-8"))
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
response_data = response_body.decode('utf-8')
else:
print("Error Code:" + rescode)
result = json.loads(response_data)
print(result)
date = [a['period'] for a in result['results'][0]['data']]
ratio_data1 = [a['ratio'] for a in result['results'][0]['data']]
ratio_data2 = [a['ratio'] for a in result['results'][1]['data']]
pd.DataFrame({'date':date,
'seraching_result':ratio_data1,
'searching_result2':ratio_data2})
아래부터 코드 분석
import pandas as pd
import urllib.request
import json가장 상단부터 데이터 분석에 특화된 pandas 모듈을 import, 다음으로 서버에 요청을을 위한 urllib.request 모듈을 요청합니다. 마지막으로 데이터를 json포맷으로 바꾸기 위한 json 모듈 import를 하면 됩니다.
client_id = "발급받은id"
client_secret = "발급받은password"
url = "https://openapi.naver.com/v1/datalab/search"다음으로 네이버 개발자 사이트에서 발급받은 API 호출 확인용 ID와 PASSWORD를 입력하고 아래 url은 동일하게 입력합니다. (ID와 PASSWORD는 Client ID와 Client Secret이다.)
body = "{\
\"startDate\":\"2022-10-01\",\
\"endDate\":\"2022-10-04\",\
\"timeUnit\":\"date\",\
\"keywordGroups\":[{\"groupName\":\"한글\",\"keywords\":[\"한글\",\"korean\"]},\
{\"groupName\":\"영어\",\"keywords\":[\"영어\",\"english\"]}\
],\
\"device\":\"pc\",\
\"ages\":[\"1\",\"2\"],\
\"gender\":\"f\"\
}";실질적으로 사용자가 원하는 데이터를 호출하는 코드입니다. 각각의 요소에 원하는 데이터를 얻기 위해 조건을 부여해야 합니다.
startData : 수집 시작일 , endData : 수집 종료일 , timeUnit : 데이터 구간 단위 설정 (date, week, month)
keywordGroups : 사용자가 원하는 키워드를 입력하는 공간이다. 그룹을 지어서 데이터를 보내야하고 그룹은 최대 5개까지 동시에 호출할 수 있다. (위 코드는 동시에 2개의 키워드를 요청) 그룹네 keywords 공간에 한글 검색어와 영문 검색어를 입력하면 됩니다.
device : pc 검색량 또는 mobile 검색량을 선택할 수 있습니다.
age : 검색 연령을 선택할 수 있다.(단위는 5)
gender : 검색 성별을 선택할 수 있습니다.
각 옵션에 대한 자세한 정보는 다음 주소를 참고하면 됩니다. https://developers.naver.com/docs/serviceapi/datalab/search/search.md#통합-검색어-트렌드
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
request.add_header("Content-Type","application/json")
response = urllib.request.urlopen(request, data=body.encode("utf-8"))
rescode = response.getcode()위에서 입력한 id, password와 검색 옵션을 취합하여 네이버 api 서버에 request 요청을 보내고 다시 응답하는 코드입니다. 사용자가 따로 수정할 필요 없으며 요청후 받은 데이터는 가장 아래에 있는 rescode 객체에 담깁니다.
if(rescode==200):
response_body = response.read()
response_data = response_body.decode('utf-8')
else:
print("Error Code:" + rescode)요청 후 응답 받은 데이터가 코드 또는 서버 오류 때문에 유실될 수 있기 때문에 응답 코드를 활용하여 if 조건문을 넣었습니다. 만약 응답이 정상 상태면 if 내부 코드가 실행되어 응답 데이터를 utf-8로 변경하여 response_data 객체에 담고 아닐 경우 error 코드와 함께 오류 메시지를 출력합니다.
result = json.loads(response_data)
print(result)데이터를 다루기 편하도록 json 타입으로 변경하고 print하여 터미널에서 확인하면 아래와 같은 결과를 확인할 수 있습니다. 파이썬 json 모듈의 loads 함수는 json 타입의 데이터를 불러오는 역할을 수행합니다.

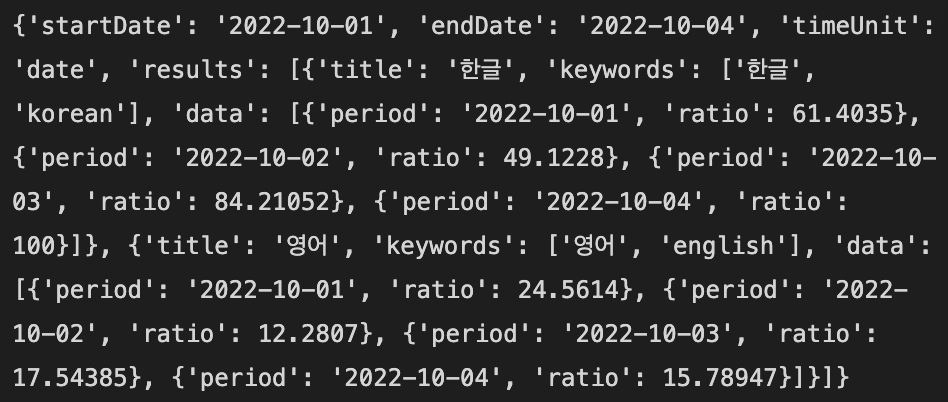
원하는 검색량 데이터를 얻었지만 사람이 식별하기 어렵기 때문에 시각적으로 가공을 진행합니다. 우선 전달 받은 데이터는 딕셔너리와 리스트의 형태를 가지기 때문에 각 데이터를 카테고리와 시키기 위해 for문을 사용하여 객체에 담아야 합니다. 그 후 편하게 가공하기 위해 pandas 모듈을 사용하면 됩니다.
date = [a['period'] for a in result['results'][0]['data']]
ratio_data1 = [a['ratio'] for a in result['results'][0]['data']]
ratio_data2 = [a['ratio'] for a in result['results'][1]['data']]상단부터 기간 데이터 / ‘한글’ 키워드에 대한 비율 데이터 / ‘영어’ 키워드에 대한 비율 데이터입니다. 각 객체들을 아래서 pandas data frame에 담아 표로 시각화 합니다.
pd.DataFrame({'date':date,
'seraching_result':ratio_data1,
'searching_result2':ratio_data2})판다스 데이터 프레임에 해당 객체를 담으면 아래와 같은 표 결과를 볼 수 있습니다.

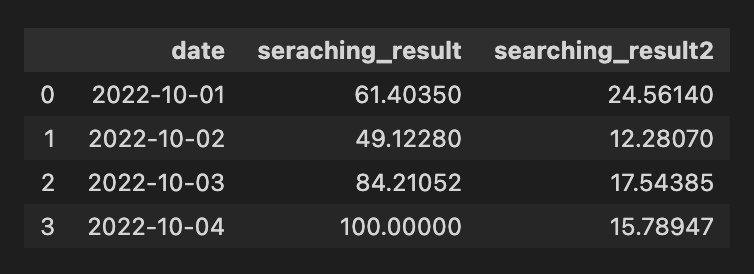
위 과정을 통해 네이버 검색 api로부터 검색 키워드에 대한 기간, 성별, 연령에 따른 자료를 받을 수 있습니다.
파이썬을 통한 데이터 가공
위에서 받은 데이터를 시각화하였지만 앞으로 SEO 분석 및 고객사에 데이터를 전달하기 위해서는 엑셀 또는 db에 데이터를 적재해야 합니다. 따라서 데이터를 .csv로 저장하는 방법에 대해서 알아보겠습니다.
데이터 활용을 위한 모듈 설치
import pandas as pd위에서 해당 모듈을 사용했기 때문에 추가로 import할 필요는 없습니다.
.csv로 가공 및 저장
우선 위 코드에서 마지막 dataFrame에 담는 데이터 코드를 수정해야 합니다. 아래 코드를 참조합시다.
tocsv = pd.DataFrame({'date':date,
'seraching_result':ratio_data1,
'searching_result2':ratio_data2})tocsv라는 객체를 선언하여 data frame으로 가공한 데이터를 담았습니다.
tocsv.to_csv('경로.csv')tocsv를 to_csv 함수를 통해 경로를 지정하면 해당 경로에 csv 확장자 파일이 생성되고 데이터가 저장됩니다.

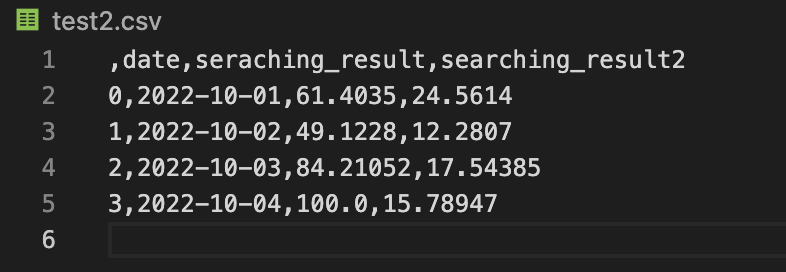
csv 포맷 파일에 데이터를 담고 해당 자료를 활용하여 검색 키워드를 분석할 수 있습니다.
이번 글을 통해 네이버 트렌드 검색 API로 부터 검색 키워드에 대한 통계 데이터를 파이썬을 이용해 요청하고 가공하는 방법에 대해서 알아보았습니다.
스마트블록에 대응해서 SEO 하는 방법에 대해서도 알아보고 싶다면, ‘네이버 스마트블록의 인기글 도입과 SEO 대응 방법‘ 글을 참고해 보세요.
운영하는 웹사이트를 네이버 포털에 대한 SEO 친화적 키워드를 찾고 검색 결과 상단에 노출하길 원하면 저희 TBWA DataLab에 문의주시면 감사하겠습니다.